
Life Beyond Distributed Transactions: An Apostate's Implementation - Dispatcher Failure Recovery

Posts in this series:
- A Primer
- Document Coordination
- Document Example
- Dispatching Example
- Failures and Retries
- Failure Recovery
- Sagas
- Relational Resources
- Conclusion
In the last post, we looked at how we can recover from exceptions from inside our code handling messages. We perform some action in our document, and something goes wrong. But what happens when something goes wrong during the dispatch process:
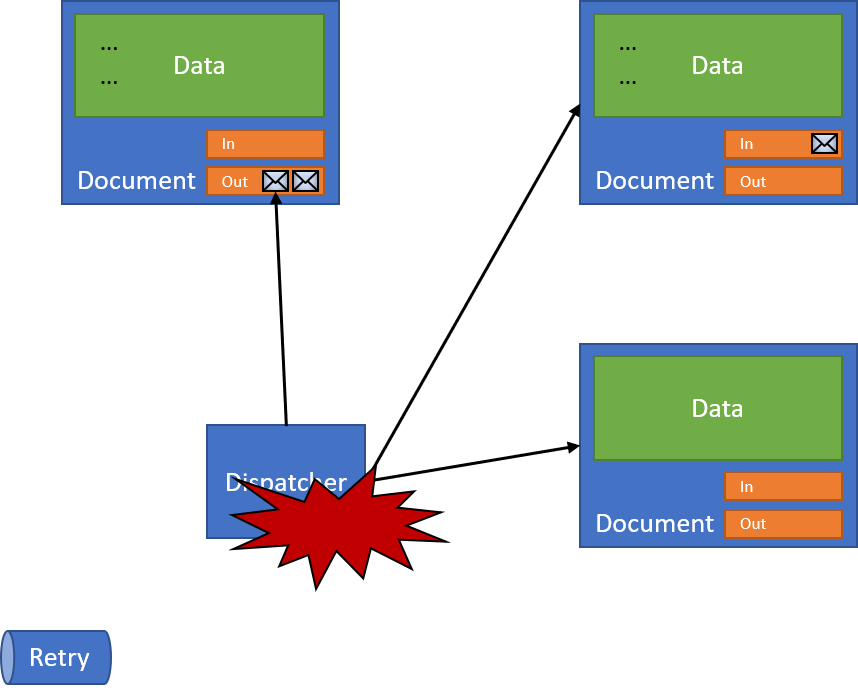
If our dispatcher itself fails, either:
- Pulling a message from the outbox
- Sending a message to the receiver
- Saving documents
Then our documents are still consistent, but we've lost the execution flow to dispatch. We've mitigated our failures somewhat, but we still can have the possibility of some unrecoverable failure in our dispatcher, and no amount of exception handling can prevent a document with a message sitting in its outbox, waiting for processing.
If we were able to wrap everything, documents and queues, in a transaction, then we could gracefully recover. However, the point of this series is that we don't have access to distributed transactions, so that option is out.
What we need is some kind of background process looking for documents with pending messages in their outbox, ready to process.
Designing the dispatch rescuer
We already have the dispatch recovery process using async messaging to retry an individual dispatch, which works great when the failure is in application code. When the failure is environmental, our only clue something is wrong is a document with messages in their outbox.
The general process to recover from these failures would be:
- Find any documents with unprocessed messages (ideally oldest first)
- Retry them one at a time
We have the possibility though that we have:
- In flight dispatching
- In flight retries
Ideally, we have some sort of lagging processor, so that when we have issues, we don't interfere with normal processing. Luckily for us, Cosmos DB already comes with the ability to be notified that documents have been changed, the Change Feed, and this change feed even lets us work with a built-in delay. After each document changes, we can wait some amount of time where we assume that dispatching happened, and re-check the document to make sure dispatching occurred.
Our rescuer will:
- Get notified when a document changes
- Check to see if there are still outbox messages to process
- Send a message to reprocess that document
It's somewhat naive, as we'll get notified for all document changes. To make our lives a little bit easier, we can turn off immediate processing for document message dispatching and just dispatch through asynchronous processes, but it's not necessary.
Creating the change feed processor
Using the documentation as our guide, we need to create two components:
- A document feed observer to receive document change notifications
- A change feed processor to host and invoke our observer
Since we already have a background processor in our dispatcher, we can simply host the observer in the same endpoint. The observer won't actually be doing the work, however - we'll still send a message out to process the document. This is because NServiceBus still provides all the logic around retries and poison messages that I don't want to code again. Like most of my integrations, I kick out the work into a durable message and NServiceBus as quickly as possible.
That makes my observer pretty small:
public class DocumentFeedObserver<T> : IChangeFeedObserver
where T : DocumentBase
{
static ILog log = LogManager.GetLogger<DocumentFeedObserver<T>>();
public Task OpenAsync(IChangeFeedObserverContext context)
=> Task.CompletedTask;
public Task CloseAsync(
IChangeFeedObserverContext context,
ChangeFeedObserverCloseReason reason)
=> Task.CompletedTask;
public async Task ProcessChangesAsync(
IChangeFeedObserverContext context,
IReadOnlyList<Document> docs,
CancellationToken cancellationToken)
{
foreach (var doc in docs)
{
log.Info($"Processing changes for document {doc.Id}");
var item = (dynamic)doc;
if (item.Outbox.Count > 0)
{
ProcessDocumentMessages message = ProcessDocumentMessages.New<T>(item);
await Program.Endpoint.SendLocal(message);
}
}
}
}
The OpenAsync and CloseAsync methods won't do anything, all my logic is in the ProcessChangesAsync method. In that method, I get a collection of changed documents. I made my DocumentChangeObserver generic because each observer observes only one collection, so I have to create distinct observer instances per concrete DocumentBase type.
In the method, I loop over all the documents passed in and look to see if the document has any messages in the outbox. If so, I'll create a new ProcessDocumentMessages to send to myself (as I'm also hosting NServiceBus in this application), which will then process the document messages.
With our simple observer in place, we need to incorporate the observer in our application startup.
Configuring the observer
For our observer, we have a couple of choices on how we want to process document changes. Because our observer will get called for every document change, we want to be careful about the work it does.
Our original design had document messages dispatched in the same request as the original work. If we keep this, we want to make sure that we minimize the amount of rework for a document with messages. Ideally, our observer only kicks out messages when there is truly something wrong with dispatching. This will also minimize the amount of queue messages, reserving them for the error case.
So a simple solution would be to just introduce some delay in our processing:
private static ChangeFeedProcessorBuilder CreateBuilder<T>(DocumentClient client)
where T : DocumentBase
{
var builder = new ChangeFeedProcessorBuilder();
var uri = new Uri(CosmosUrl);
var dbClient = new ChangeFeedDocumentClient(client);
builder
.WithHostName(HostName)
.WithFeedCollection(new DocumentCollectionInfo
{
DatabaseName = typeof(T).Name,
CollectionName = "Items",
Uri = uri,
MasterKey = CosmosKey
})
.WithLeaseCollection(new DocumentCollectionInfo
{
DatabaseName = typeof(T).Name,
CollectionName = "Leases",
Uri = uri,
MasterKey = CosmosKey
})
.WithProcessorOptions(new ChangeFeedProcessorOptions
{
FeedPollDelay = TimeSpan.FromSeconds(15),
})
.WithFeedDocumentClient(dbClient)
.WithLeaseDocumentClient(dbClient)
.WithObserver<DocumentFeedObserver<T>>();
return builder;
}
The ChangeFeedProcessorBuilder is configured for every document type we want to observe, with a timespan in this example of 15 seconds. I could bump this up a bit - say to an hour or so. It will really depend on the business, the SLAs they expect for work to complete.
Finally, in our application startup, we need to create the builder, processor, and start it all up:
Endpoint = await NServiceBus.Endpoint.Start(endpointConfiguration)
.ConfigureAwait(false);
var builder = CreateBuilder<OrderRequest>(client);
var processor = await builder.BuildAsync();
await processor.StartAsync();
Console.WriteLine("Press any key to exit");
Console.ReadKey();
await Endpoint.Stop()
.ConfigureAwait(false);
await processor.StopAsync();
With this in place, we can have a final guard against failures, assuming that someone completely pulled the plug on our application and all we have left is a document with messages sitting in its outbox.
In our next post, we'll look at using sagas to coordinate changes between documents - what happens if we want either all, or none of our changes to be processed in our documents?