
Composite UIs for Microservices - Data Composition

Posts in this series:
In the last post, we looked at composing at the server side, both through composing through widgets/components, and then for data sources for a widget themselves, using model composition to pull data from multiple sources into a single model.
In model composition, a single set of inputs fans out to multiple services for data, returned back and composed into a single model:
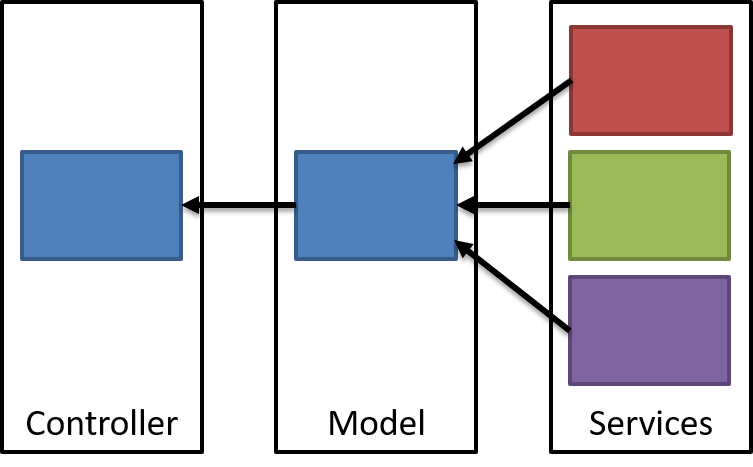
There is a downside to the approach, however. The needs of the overall model will force requirements into the composed services, both in terms of the API results returned and latency/uptime.
Data Modeling
For many systems I work with, it's difficult to push end-user-facing requirements all the way into back-end systems that just aren't built for the load of the front end. Neither is their data in any relevant shape for the front end.
In these cases, it often makes sense to compose the data before making our request. Suppose we have a search page in our system, where we're searching information across many different services:

Our search page lets us search a variety of different options, but these options are across many different services:

It's really not possible to push the searching capabilities down into each constituent service. For one, those services really don't know how to perform a search, they're just not built for it.
The other major issue is that search relevance needs to combine different sources with rankings, and that's really not possible when all these services have to own both their service AND a highly specific capability for the front end.
Instead, we actually have a new service that arises:
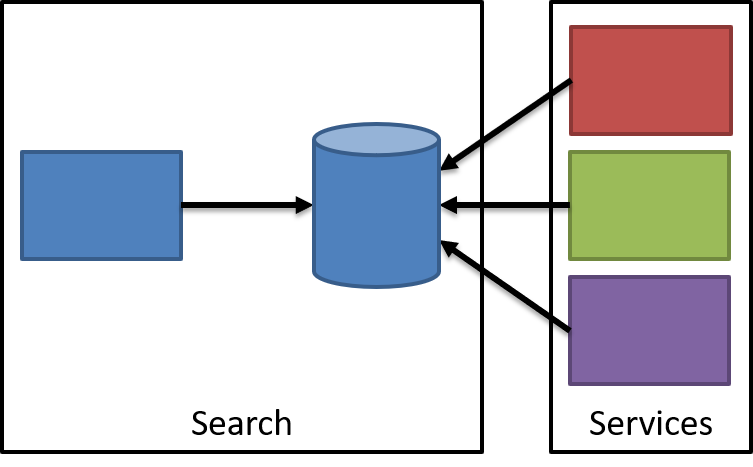
The search service now only talks to its own specialized data store to perform a search. The data inside of the search database includes (stale) data from other services, as a read-only format. For example, search includes the product prices from the Pricing service, but it doesn't own the pricing data. As Pat Helland's talk on immutability describes, once data is immutable (events), we are free to distribute that data as much as we like, as long as consumers respect the immutability. Our search service can't reject the price and apply a new one.
Once we embrace the immutability of messages, we can safely distribute our data, with the known tradeoff that the information will have a greater staleness than say going to the service directly. It's a tradeoff.
But in the case of our search service, it's really the only viable option. There are many other cases like this - reporting, analytics, AI/ML, and any other system where I'm trying to get a broader view, making business decisions on data that isn't in an appropriate format in the transactional system.
Exposing service data
This is an emerging space, where techniques such as event sourcing and log streams (e.g. Kafka) allow systems to expose their events in such a way that allow ingesters to consume these messages in any way they see fit.
Of course, we can also used timeworn integration techniques, including:
- Messaging to react to changes as they happen
- APIs/web services to periodically poll for changes
- File-based exports to pull in bulk data from relatively static sources
Nearly every service-oriented system I've dealt with has needed data composition, simply for the need to move the data closer to the consumer and into a more consumable format for the service. These weren't compromises or bad decisions, it's just another option to look at.
In the last post in the series, I'll wrap up our different options and how we can decide what the right direction to chose.