
Refactoring Towards Resilience: Evaluating SendGrid Options

Other posts in this series:
- A primer
- Evaluating Stripe Options
- Evaluating SendGrid Options
- Evaluating RabbitMQ Options
- Evaluating Coupling
- Async Workflow Options
- Process Manager Solution
In the last post, we found we had the full gamut of options for coordinating our distributed activity:
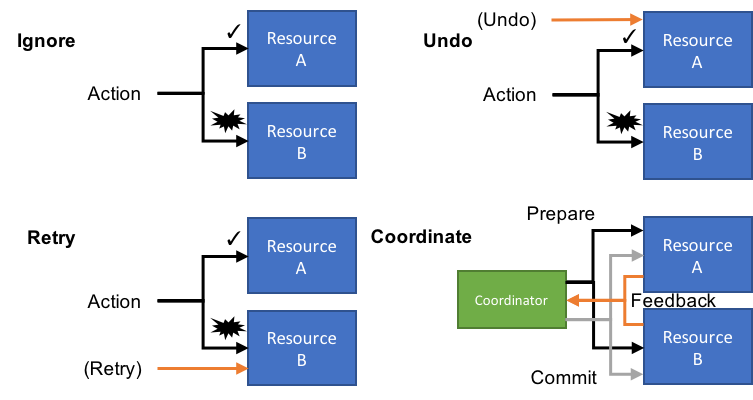
We could ignore the failure (and have money floating in the ether), retry using an idempotency key, undo via a refund, or coordinate using the auth/capture flow Stripe provides. That's quite helpful that we have so many options available, it lets us be flexible in our approach. Part of this is the design of the Stripe API, and part is just the nature of payments.
SendGrid, a service to send email, naturally won't have as many options. The purpose of SendGrid is to send emails when you call their API, and to send that email as quickly as possible. You shouldn't call their API unless you want an email sent. With this in mind, let's look at our coordination options.
Ignore
With Stripe, the Ignore option wasn't really viable. We need to charge customers, but we don't want to charge them twice. With an email notification, it's not necessarily as critical.
In our original code, any SendGrid failure caused my entire process to fail:
public async Task<ActionResult> ProcessPayment(CartModel model) {
var customer = await dbContext.Customers.FindAsync(model.CustomerId);
var order = await CreateOrder(customer, model);
var payment = await stripeService.PostPaymentAsync(order);
await sendGridService.SendPaymentSuccessEmailAsync(order);
await bus.Publish(new OrderCreatedEvent { Id = order.Id });
return RedirectToAction("Success");
}
But what if it doesn't have to be this way? Does a SendGrid failure really need to take my entire payment process down? Should I not take people's money because I can't send them an email? Maybe not! The simplest approach would be just to ignore (and log) failures:
public async Task<ActionResult> ProcessPayment(CartModel model) {
var customer = await dbContext.Customers.FindAsync(model.CustomerId);
var order = await CreateOrder(customer, model);
var payment = await stripeService.PostPaymentAsync(order);
try {
await sendGridService.SendPaymentSuccessEmailAsync(order);
} catch (Exception e) {
Logger.Exception(e, $"Failed to send payment email for order {order.Id}");
}
await bus.Publish(new OrderCreatedEvent { Id = order.Id });
return RedirectToAction("Success");
}
We'd still want to send emails, but we can be notified of these exceptions and have some manual (or automated) process to retry emails.
Retry
Unlike Stripe, SendGrid does not support any sort of idempotency in requests. This is intentional on their part, they want to send emails as soon as possible and introducing any sort of idempotency check would introduce a delay in the send.
All this means that Retrying a SendGrid call would result in two emails sent. Is this acceptable? Probably not - if I received two "payment successful" emails, I would rightly freak out and assume my card was charged twice.
Fundamentally, my emails are SMTP, another messaging protocol, which just doesn't support something like idempotent Retry. If I wanted true retries, I would need to build a resiliency layer on top of sending emails, something that SendGrid (and most email service providers I can think of) do not do.
No retries.
Undo
Similar to Undo, there's really no such thing as "undoing" an email sent. Perhaps a follow-up email "ignore that last email", but that's about it.
SendGrid does however support scheduling emails in a batch with an ID, and cancelling a batch. However, there are limitations to batches sent, and batches are as the name implies a means to send a bunch of emails at a time in a batch.
I don't really want to be tied to scheduling a batch of emails together, as the customer expectation is to get an email relatively soon after send, and I can't create a batch for every single email.
No undos.
Coordinate
Similar to Retry, there's really no facility to coordinate an email send with some sort of two-phase commit process. I'd have to build something on top of calling the SendGrid API to coordinate this action.
No coordination.
So where does that leave us? In our current state, we can either Retry or Ignore. Neither are great solutions, but we'll come back soon on better ways to tackle this problem with messaging.
Next up, RabbitMQ failures!