
Life Beyond Distributed Transactions: An Apostate's Implementation - Failures and Retries

Posts in this series:
- A Primer
- Document Coordination
- Document Example
- Dispatching Example
- Failures and Retries
- Failure Recovery
- Sagas
- Relational Resources
- Conclusion
In the last post, we looked at an example of dispatching document messages to other documents using a central dispatcher. Our example worked well in the happy path scenario, but what happens when something goes wrong? We of course do not want a failure in dispatching messages to make the entire request fail, but what would that mean for us?
We described a general solution to put the dispatching work aside using queues and messaging, effectively saying "yes, dispatching failed, so let's put it aside to look at in the future". This would allow the overall main request to complete:
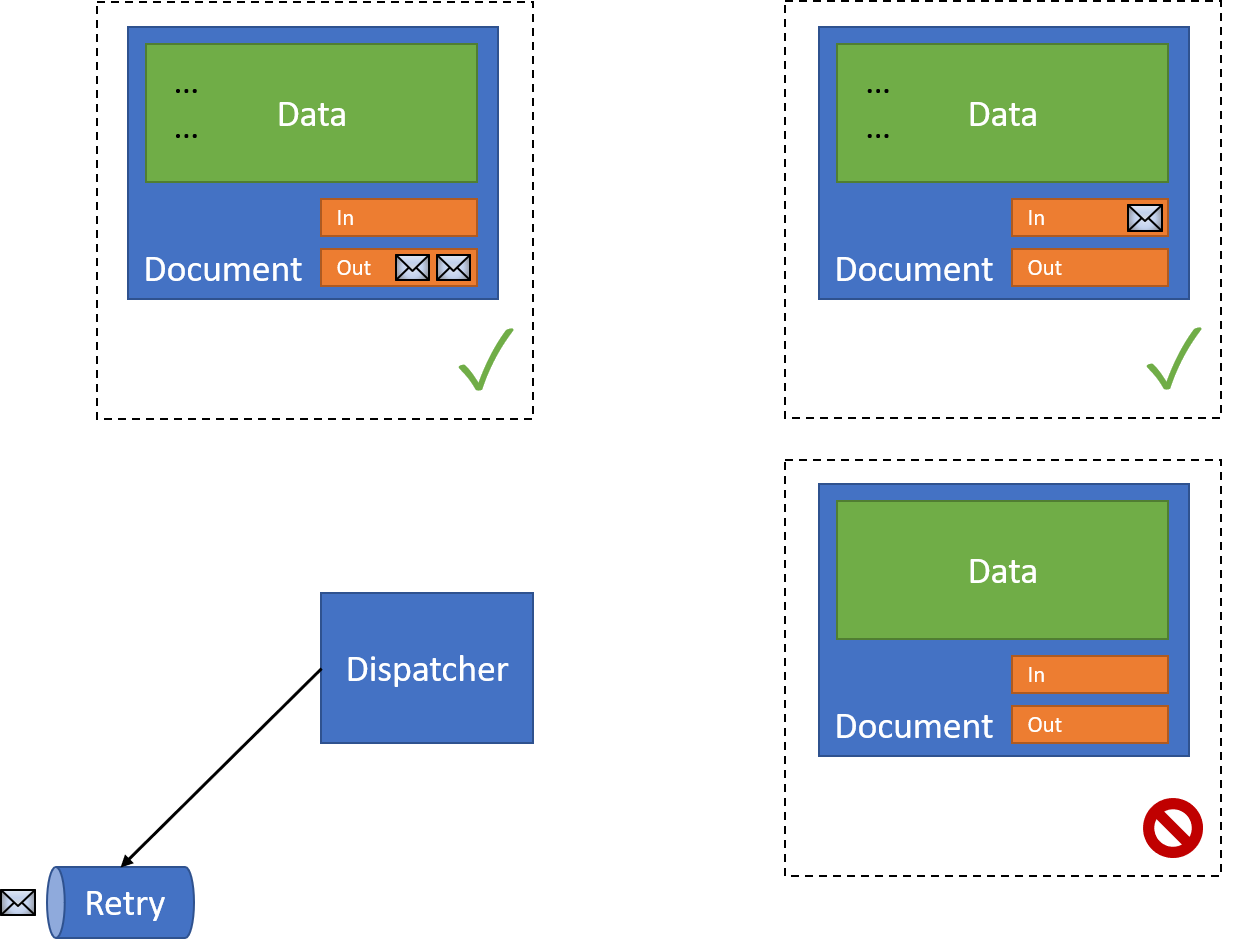
Our original example also assumed that we would dispatch our messages immediately in the context of the same request, which isn't a bad default but maybe isn't always desirable. Let's first look at the scenario of dispatching immediately, and what failures could mean.
Characterizing our failures
Dispatching failures could happen for a number of reasons, but I generally see a continuum:
- Transient
- Delayed
- Permanent
My failures usually have some sort of time component associated with them. A transient failure may mean that if I simply try the action again immediately, it may work. This most often comes up with some sort of concurrency violation against the database.
Delayed failures are a bit different, where I won't succeed if I try immediately, but I will if I just wait some amount of time.
Permanent failures mean there's an unrecoverable failure, and no amount of retries will allow the operation to succeed.
Of course, we could simply ignore failures, but our business and customers might not agree with that approach. How might we handle each of these kinds of failures?
Transient failures
If something goes wrong, can we simply retry the operation? That seems fairly straightforward - but we don't want to retry too many times. We can implement some simple policies, either with a hardcoded number of retries or using something like the Polly Project to retry an action.
To keep things simple, we can have a policy to address the most common transient failure - optimistic concurrency problems. We first want to enable OCC checks, of course:
public async Task<Document> UpdateItemAsync(T item)
{
var ac = new AccessCondition
{
Condition = item.ETag,
Type = AccessConditionType.IfMatch
};
return await _client.ReplaceDocumentAsync(
UriFactory.CreateDocumentUri(DatabaseId, CollectionId, item.Id.ToString()),
item,
new RequestOptions { AccessCondition = ac });
}
When we get a concurrency violation, this results in a DocumentClientException with a special status code (hooray HTTP!). We need some way to wrap our request and retry if necessary - time for another MediatR behavior! This one will retry our action some number of times:
public class RetryUnitOfWorkBehavior<TRequest, TResponse>
: IPipelineBehavior<TRequest, TResponse>
{
private readonly IUnitOfWork _unitOfWork;
public RetryUnitOfWorkBehavior(IUnitOfWork unitOfWork)
=> _unitOfWork = unitOfWork;
public Task<TResponse> Handle(
TRequest request,
CancellationToken cancellationToken,
RequestHandlerDelegate<TResponse> next)
{
var retryCount = 0;
while (true)
{
try
{
return next();
}
catch (DocumentClientException e)
{
if (e.StatusCode != HttpStatusCode.PreconditionFailed)
throw;
if (retryCount >= 5)
throw;
_unitOfWork.Reset();
retryCount++;
}
}
}
}
If our action files due to a concurrency problem, we need to clear out our unit of work's identity map and try again:
public void Reset()
{
_identityMap.Clear();
}
Then we just need to register our behavior with the container like our original unit of work behavior, and we're set. We could have of course modified our original behavior to add retries - but I want to keep them separate because they truly are different concerns.
That works for immediate failures, but we still haven't looked at failures in our message dispatching. For that, we'll need to involve some messaging.
Deferred dispatching with messaging and NServiceBus
The immediate retries can take care of transient failures during a request, but if the there's some deeper issue, we want to defer the document message dispatching to some time in the future. To make my life easier, and not have to implement half the Enterprise Integration Patterns book myself, I'll leverage NServiceBus to manage my messaging.
Our original dispatcher looped through our unit of work's identity map to find documents with messages that need dispatching. We'll want to augment that behavior to catch any failures, and dispatch those messages offline:
public interface IOfflineDispatcher
{
Task DispatchOffline(DocumentBase document);
}
Our Complete method of the unit of work will now take these failed dispatches and instruct our offline dispatcher to dispatch these offline:
public async Task Complete()
{
var toSkip = new HashSet<DocumentBase>(DocumentBaseEqualityComparer.Instance);
while (_identityMap
.Except(toSkip, DocumentBaseEqualityComparer.Instance)
.Any(a => a.Outbox.Any()))
{
var document = _identityMap
.Except(toSkip, DocumentBaseEqualityComparer.Instance)
.FirstOrDefault(a => a.Outbox.Any());
if (document == null)
continue;
var ex = await _dispatcher.Dispatch(document);
if (ex != null)
{
toSkip.Add(document);
await _offlineDispatcher.DispatchOffline(document);
}
}
}
This is a somewhat naive implementation - it doesn't allow for partial document message processing. If a document has 3 messages, we mark the retry the entire document instead of an individual message at at time. We could manage this more granularly, by including a "retry" collection on our document. But this introduces more issues - we could still have some system failure after dispatch and our document message never make it to retry.
When our transaction scope is individual operations instead of the entire request, we have to assume failure at every instance and examine what might go wrong.
The offline dispatcher uses NServiceBus to send a durable message out:
public class UniformSessionOfflineDispatcher
: IOfflineDispatcher
{
private readonly IUniformSession _uniformSession;
public UniformSessionOfflineDispatcher(IUniformSession uniformSession)
=> _uniformSession = uniformSession;
public Task DispatchOffline(DocumentBase document)
=> _uniformSession.Send(ProcessDocumentMessages.New(document));
}
The IUniformSession piece from NServiceBus to send a message from any context (in a web application, backend service, etc.). Our message just includes the document ID and type:
public class ProcessDocumentMessages : ICommand
{
public Guid DocumentId { get; set; }
public string DocumentType { get; set; }
// For NSB
public ProcessDocumentMessages() { }
private ProcessDocumentMessages(Guid documentId, string documentType)
{
DocumentId = documentId;
DocumentType = documentType;
}
public static ProcessDocumentMessages New<TDocument>(
TDocument document)
where TDocument : DocumentBase
{
return new ProcessDocumentMessages(
document.Id,
document.GetType().AssemblyQualifiedName);
}
}
We can use this information to load our document from the repository. With this message in place, we now need the component that will receive our message. For this, it will really depend on our deployment, but for now I'll just make a .NET Core console application that includes our NServiceBus hosting piece and a handler for that message:
I won't dig too much into the NServiceBus configuration as it's really not that germane, but let's look at the handler for that message:
public class ProcessDocumentMessagesHandler
: IHandleMessages<ProcessDocumentMessages>
{
private readonly IDocumentMessageDispatcher _dispatcher;
public ProcessDocumentMessagesHandler(IDocumentMessageDispatcher dispatcher)
=> _dispatcher = dispatcher;
public Task Handle(ProcessDocumentMessages message, IMessageHandlerContext context)
=> _dispatcher.Dispatch(message);
}
Also not very exciting! This class is what NServiceBus dispatches the durable message to. For our simple example, I'm using RabbitMQ, so if something goes wrong our message goes into a queue:

Our handler receives this message to process it. The dispatcher is slightly different, as it needs to work with a message instead of an actual document, so it needs to load it up first:
public async Task Dispatch(ProcessDocumentMessages command)
{
var documentType = Type.GetType(command.DocumentType);
var repository = GetRepository(documentType);
var document = await repository.FindById(command.DocumentId);
if (document == null)
{
return;
}
foreach (var message in document.Outbox.ToArray())
{
var handler = GetHandler(message);
await handler.Handle(message, _serviceFactory);
document.ProcessDocumentMessage(message);
await repository.Update(document);
}
}
One other key difference in this dispatch method is that we don't wrap anything in any kind of try-catch to report back errors. In an in-process dispatch mode, we still want the main request to succeed. In the offline processing mode, we're only dealing with document dispatching. And since we're using NServiceBus, we can rely on its built-in recoverability behavior with immediate and delayed retries, eventually moving messages to an error queue.
With this in place, we can put forth an optimistic, try-immediately policy, but fall back on durable messaging if something goes wrong with our immediate dispatch. It's not bulletproof, and in the next post, I'll look at how we can implement some sort of doomsday scenario, where we have a failure between dispatch failure and queuing the retry message.