
Dealing With Optimistic Concurrency Control Collisions

Optimistic Concurrency Control (OCC) is a well-established solution for a rather old problem - handling two (or more) concurrent writes to a single object/resource/entity without losing writes. OCC works (typically) by including a timestamp as part of the record, and during a write, we read the timestamp:
- Begin: Record timestamp
- Modify: Read data and make tentative changes
- Validate: Check to see if the timestamp has changed
- Commit/Rollback: Atomically commit or rollback transaction
Ideally, step 3 and 4 happen together to avoid a dirty read. Most applications don't need to implement OCC by hand, and you can rely either on the database (through snapshot isolation) or through an ORM (Entity Framework's concurrency control). In either case, we're dealing with concurrent writes to a single record, by chucking one of the writes out the window.
But OCC doesn't tell us what to do when we encounter a collision. Typically this is surfaced through an error (from the database) or an exception (from infrastructure). If we simply do nothing, the easiest option, we return the error to the client. Done!
However, in systems where OCC collisions are more likely, we'll likely need some sort of strategy to provide a better experience to end users. In this area, we have a number of options available (and some we can combine):
- Locking
- Retry
- Error out (with a targeted message)
My least favorite is the first option - locking, but it can be valuable at times.
Locking to avoid collisions
In this pattern, we'll have the user explicitly "check out" an object for editing. You've probably seen this with older CMS's, where you'll look at a list of documents and some might say "Checked out by Jane Doe", preventing you from editing. You might be able to view, but that's about it.
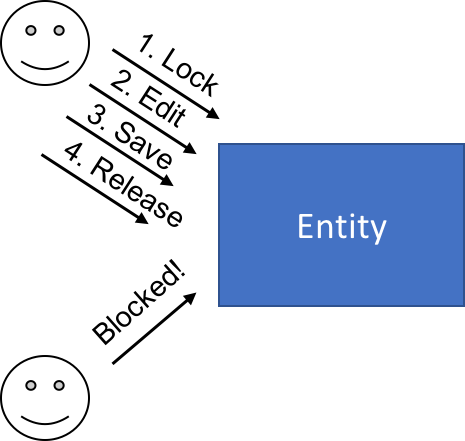
While this flow can work, it's a bit hostile for the user, as how do we know when the original user is done editing? Typically we'd implement some sort of timeout. You see this in cases of finite resources, like buying a movie ticket or sporting event. When you "check out" a seat, the browser tells you "You have 15:00 to complete the transaction". And the timer ticks down while you scramble to enter your payment information.
This kind of flow makes better sense in this scenario, when our payment is dependent on choosing the seat we want. We're also explicit to the user who is locking the item with a timeout message counter, and explicit to other users by simply not showing those seats as available. That's a good UX.
I've also had the OTHER kind of UX, where I yell across the cube farm "Roger are you done editing that presentation yet?!?"
Retry
Another popular option is to retry the transaction, steps 1-4 above. If someone has edited the record from under us, we just re-read the record including the timestamp, and try again. If we can detect this kind of exception, from a broad category of transient faults, we can safely retry. If it's a more permanent exception, validation error or the like, we can fall back to our normal error handling logic.
But how much should we retry? One time? Twice? Ten times? Until the eventual heat death of the universe? Well, probably not that last one. And will an immediate retry result in a higher likelihood of success? And in the meantime, what is the user doing? Waiting?
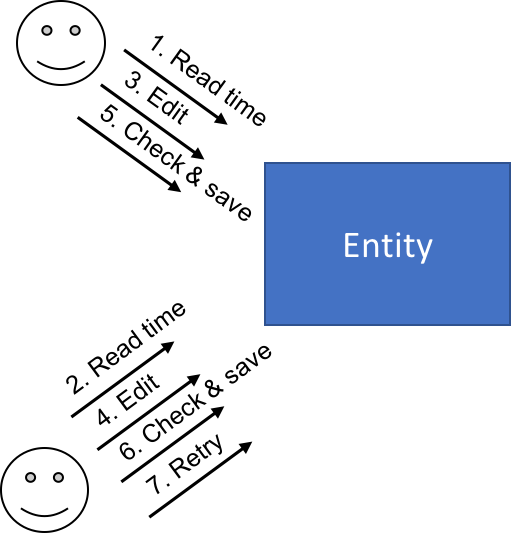
With an immediate error returned to the user, we leave it up to them to decide what to do. Ideally we've combined this with option number 3, and give them a "please try again" message.
That still leaves the question - if we retry, what should be our strategy?
It should probably be no surprise here that we have a lot of options on retries, and also a lot of literature on how to handle them.
Before we look at retry options, we should go back to our user - a retry should be transparent to them, but we do need to set some bounds here. Assuming that this retry is happening as the result of a direct user interaction where they're expecting a success or failure as the result of the interaction, we can't just retry forever.
Regardless of our retry decision, we must return some sort of result to our user. A logical timeout makes sense here - how about we just make sure that the user gets something back within time T. Maybe that's 2 seconds, 5 seconds, 10 seconds, this will be highly dependent on your end user's expectation. If they're already dealing with a highly contentious resource, waiting might be okay for them.
The elephant
One option I won't discuss, but is worth considering, is to design your entity so that you don't need concurrency control. This could include looking at eventually consistent data structures like CRDTs, naturally idempotent structures like ledgers, and more. For my purposes, I'm going to assume that you've exhausted these options and really just need OCC.
In the next post, I'll take a look at a few retry patterns and some ways we can incorporate them into a simple web app.