
Containers - What Are They Good For? Local Dependencies

Containers, huh, good god
What is it good for?
Local Dependencies!
- Edwin Starr (also disputed)
In the last post, I walked through our typical development pipeline, from local dev to production:

Now for most of our developers, when we start a new project, we can just continue to work on our existing host machine. The development dependencies don't change that much from project to project, and we're on projects typically for 6-12 months. We're not typically switching from project to project, nor do we work on multiple projects as the norm.
So our "normal" dev dependencies are:
- Some recent version Visual Studio (hopefully the latest)
- Some recent version and any SKU of SQL Server (typically SQL Express)
The most we run into are connection strings being different because of different instance names. However, this isn't universal, and we sometimes have wonky VPN requirements and such, so a developer might do something like:

The entire development environment is in a virtual machine, so that its dependencies don't get mucked with the host, and vice-versa. The downside to this approach is maintaining these images is a bit of a pain - Visual Studio is large, and so is SQL Server, so it's not uncommon that these VMs get into the tens, even over 100 GB in size.
Then we have more exotic scenarios, such as dependencies that don't run too great on Windows, or are a pain to set up, or can't play nice with other versions. For this, we can look at Docker as a means to isolate our dependencies:
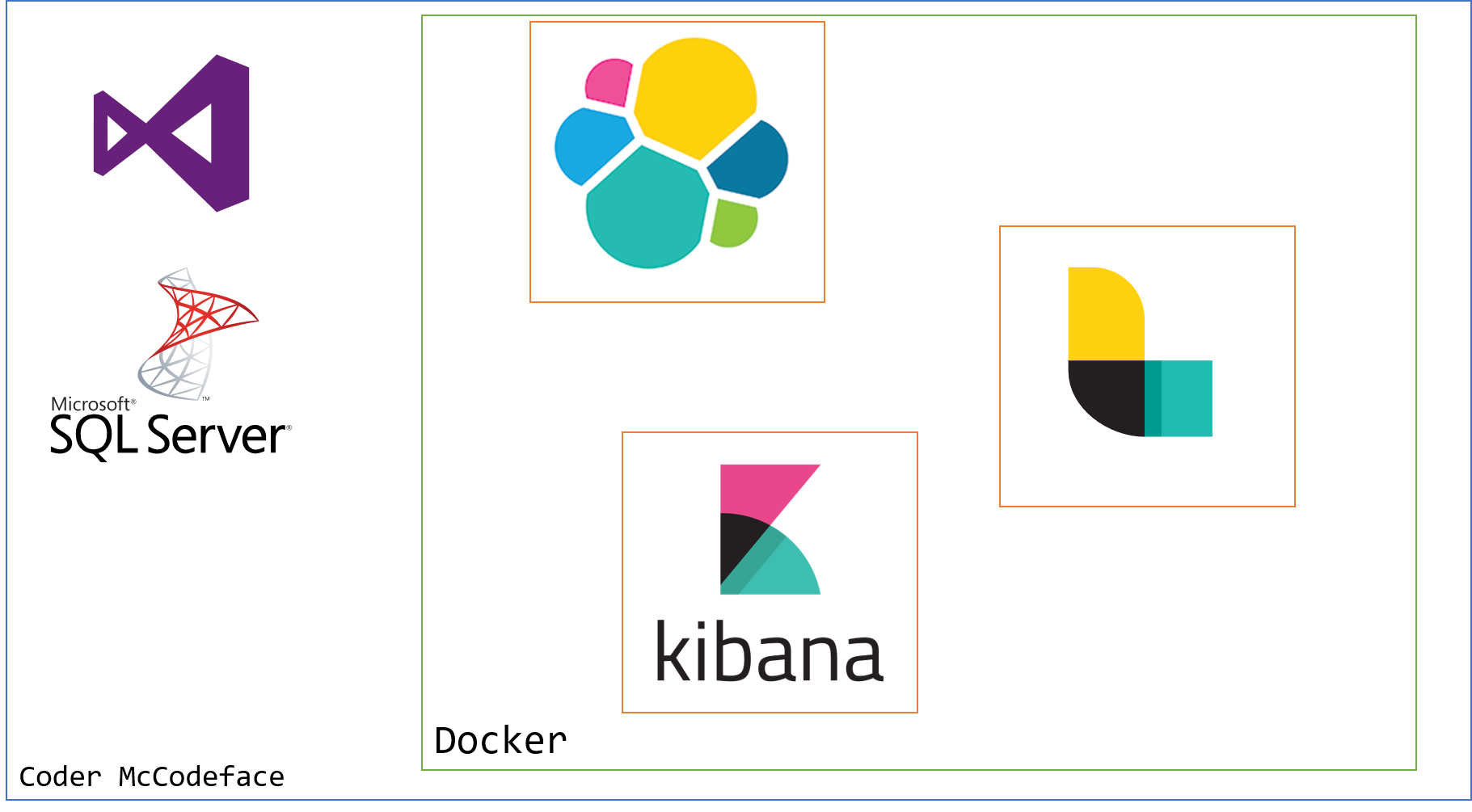
In this case, we've got the Elastic Stack we need to run for local development, but instead of installing it, we run it locally in Docker.
Docker compose for local dependencies
When we run our application like this, we're still running the main app on our host machine, but it connects to a set of Docker images for the dependencies. Docker-compose is a great tool for multi-container setups. If we wanted to just run one image, it's too bad with regular Docker, but docker-compose makes it dirt simple to do so.
For example, in my Respawn project, I support a number of different databases, and I don't really want to install them all. Instead, I have a simple docker-compose.yml file:
version: '3'
services:
postgres-db:
image: postgres
restart: always
environment:
POSTGRES_USER: docker
POSTGRES_PASSWORD: Password12!
ports:
- 8081:5432
mysql-db:
image: mysql
restart: always
environment:
MYSQL_ROOT_PASSWORD: testytest
ports:
- 8082:3306
oracle:
image: sath89/oracle-12c
restart: always
ports:
- 8080:8080
- 1521:1521
adminer:
image: adminer
restart: always
ports:
- 8083:8083
I pull in Postgres, MySQL, and Oracle (as well as a simple Admin UI), and expose these services externally via some well-known ports. When I run my build, I start these services:
docker-compose up -d
Now when my build runs, the tests connect to these services through the configured ports.
So this is a big win for us - we don't have to install any 3rd-party services on our dev machines. Instead, we pull down (or build our own) Docker images and run those.
What about normal scenarios?
The above works great for "exotic" dependencies outside our normal toolbelt, like databases, queues, and services. But most systems we build are just on top of SQL Server, which most everyone has installed already. If not SQL Express, then SQL Local DB.
But I'm in an experimenting mood, what if we did this?

This is possible today - Microsoft have their full-blown SQL Server images on Docker Hub, both in the form of SQL Server Developer Edition, and Express. There is a Linux image, but we don't run SQL Server on Linux in production so I'm not sure if there would be a difference locally or not.
So this does work, we can ignore whatever SQL a user might have installed and just say "run the database through Docker".
There are some downsides to this approach, however:
- It's running in Docker, not a Windows Service. You have to always run Docker to run your database
- The images are huuuuuuuuge
Huge images are just a thing for Windows-based containers (unless you're running Nanoserver). Take a look at the image sizes for SQL Express:
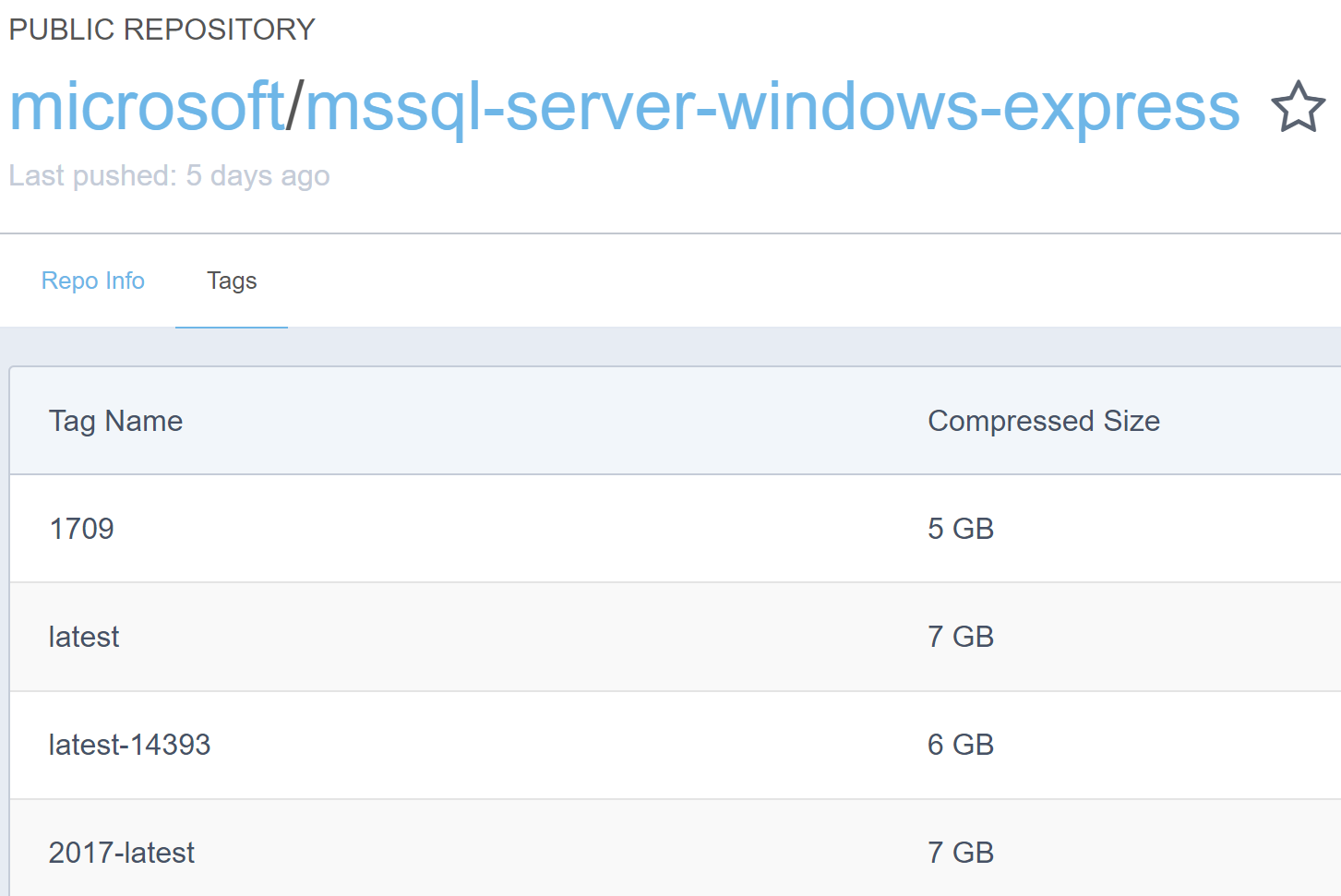
SQL Server on Linux containers are smaller, but still large, around 450MB. Compare this to Postgres on Alpine Linux:
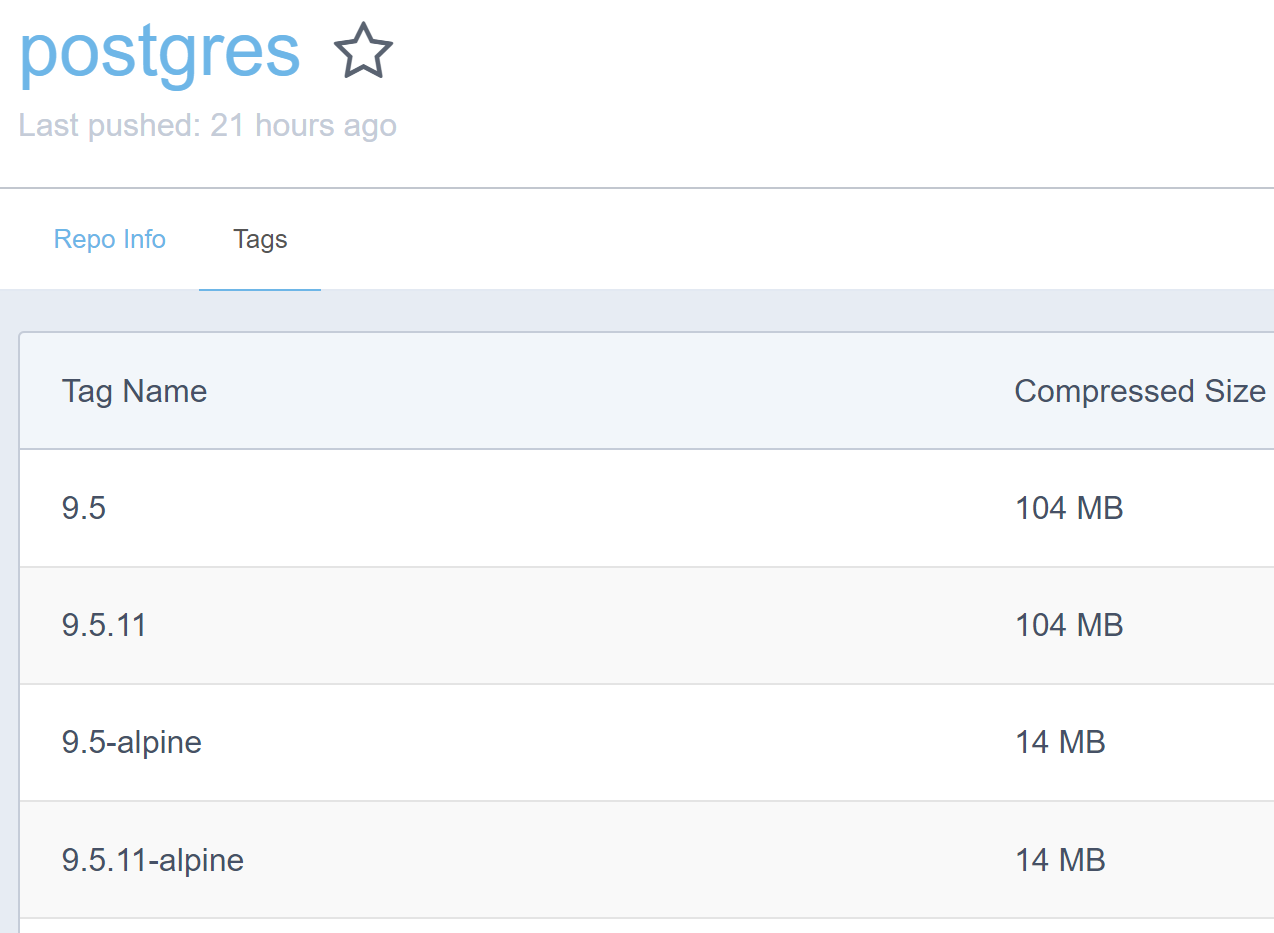
So the smallest SQL Linux image is over 30x bigger than the smallest Postgres image, and the smallest Windows SQL image is over 350x bigger. That's....ridiculous.
What does this actually mean for us locally? Docker images and layers are cached, so once you've got the base images that these SQL images are based on downloaded once, subsequent Docker pulls will only pull the additional images. For us, this would be Windows Server Core images (not Nanoserver), so you might already have this downloaded. Or not.
Startup time won't really be affected, it's about the same to start a Docker SQL container as it is to start say the SQL Server local service on the host machine, but that's still seconds.
Because of this, for our normal development experience, it's not really any better nor solving a pain that we have.
Taking it up to 11
I talked to quite a few developers who do a lot of local development in Docker, and it seemed to come down to that they are Node developers, and one thing Node is a bit lousy about is global dependencies. If you run npm install -g, then depending on what's already in your cache, or what version of node or npm running, you'll get different results.
And I also have talked to folks that have run their entire development environment inside of containers, so it looks something like:
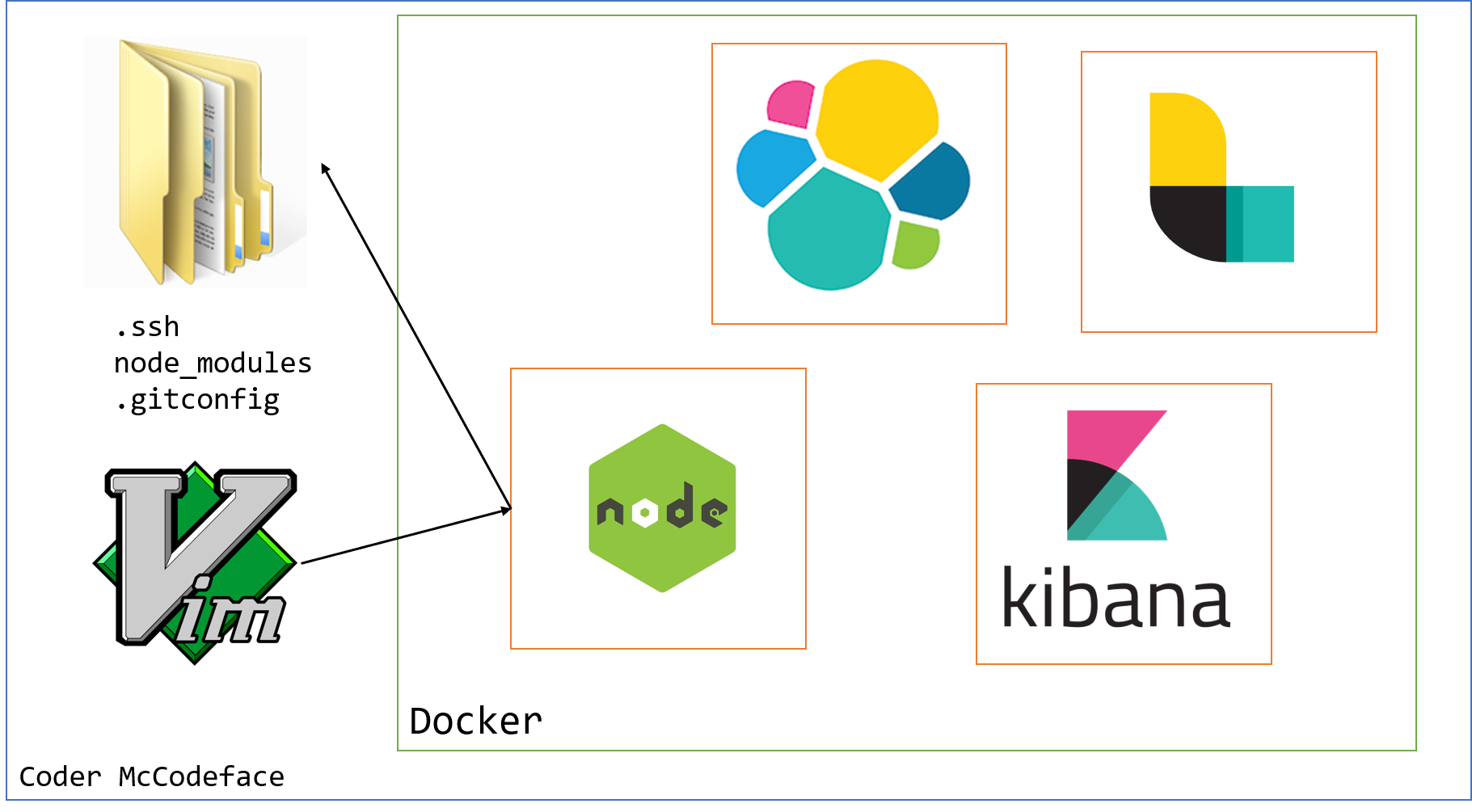
The host machine might just include some caches, but we could run everything inside containers. Development environment, editors, our source, everything. This seemed like a great way to avoid Node/Ruby pollution on a host machine, but this person also did things like:
For a normal .NET developer, I'm likely not using vim all day, and I want to do things like use a debugger. It's unlikely then that I'd move all of my development environment into a container.