
Life Beyond Distributed Transactions: An Apostate's Implementation - Document Coordination

Posts in this series:
- A Primer
- Document Coordination
- Document Example
- Dispatching Example
- Failures and Retries
- Failure Recovery
- Sagas
- Relational Resources
- Conclusion
Quick note - I've updated this post to use the more accurate term "Document" than the less-accurate, DDD-specific term "Aggregate". In the images, it still has the older term "Aggregate", let's pretend I fixed all those images.
In the last post, I walked through the general problem of distributed transactions, and some potential ideas around coordinating activities between similar or disparate resources. In a lot of cases, I would prefer to simply wrap our actions in a transaction, but as the resources I'm trying to transact together move further apart (process-wise or network-wise), transactions between these multiple resources becomes impossible.
If I can only perform reliable transactions with a single resource at a time, whether that resource is a database or single record in Cosmos DB, I need to design my interactions so that both the business data and communications transact together. That means that my communication needs to be in the same transactional store as my business data!
In the case of Azure Cosmos DB, I need to place my communication that I both send and receive inside my document. I store incoming communication because any request to change data needs to be idempotent. I could just have some business rule "all actions must be idempotent", I can also achieve this by simply storing the incoming requests and checking to see if I've already processed this request before performing the action.
For outgoing communication, I can't interact with any other resource transactionally, so I store outgoing communication on what I can control - the document. So our final document looks like:
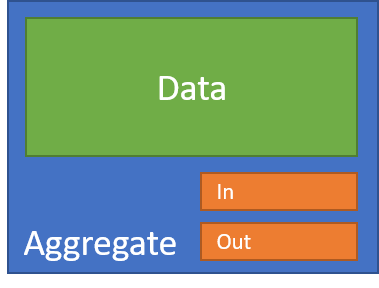
When I perform an operation, communication and business data either save successfully or the entire operation rolls back.
Dispatching Changes
When I find I have an operation that needs to affect more than one resource, I then use my outbox to communicate with those external resources:
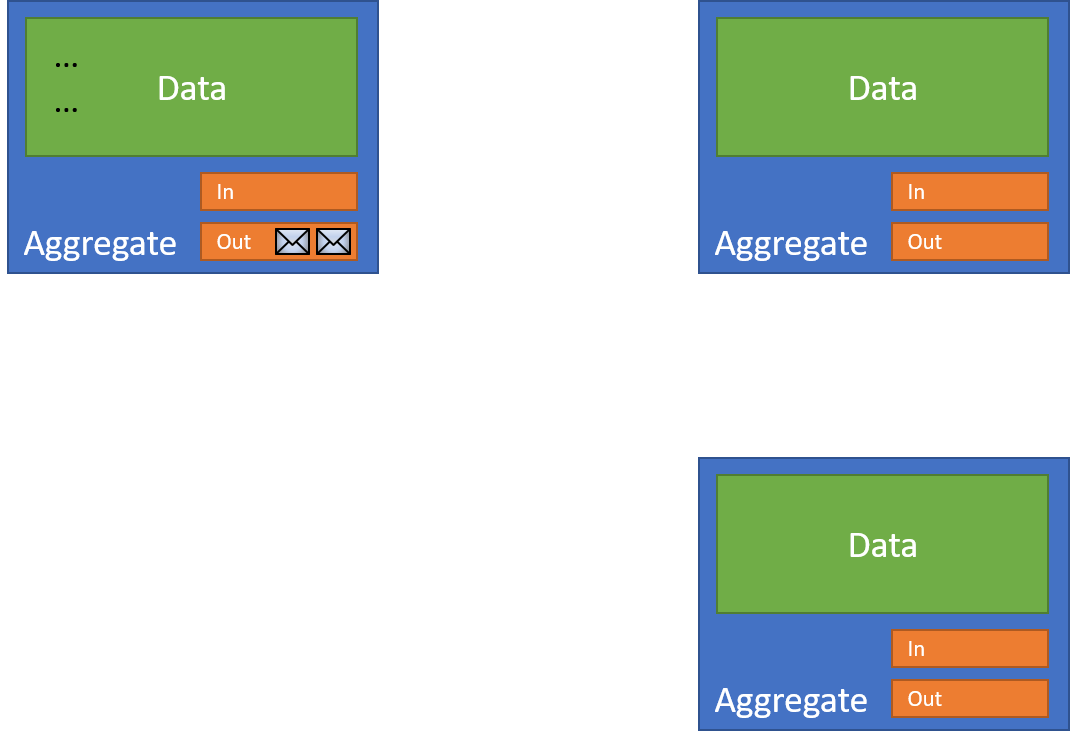
I can then safely transact that single resource:
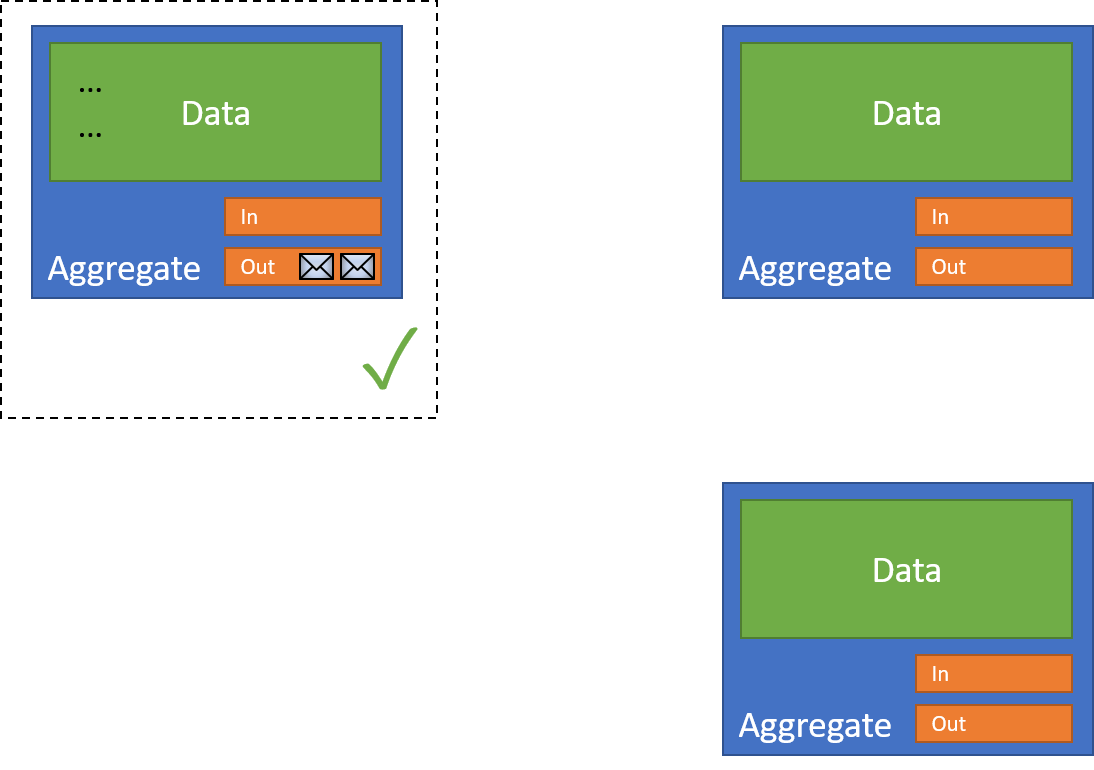
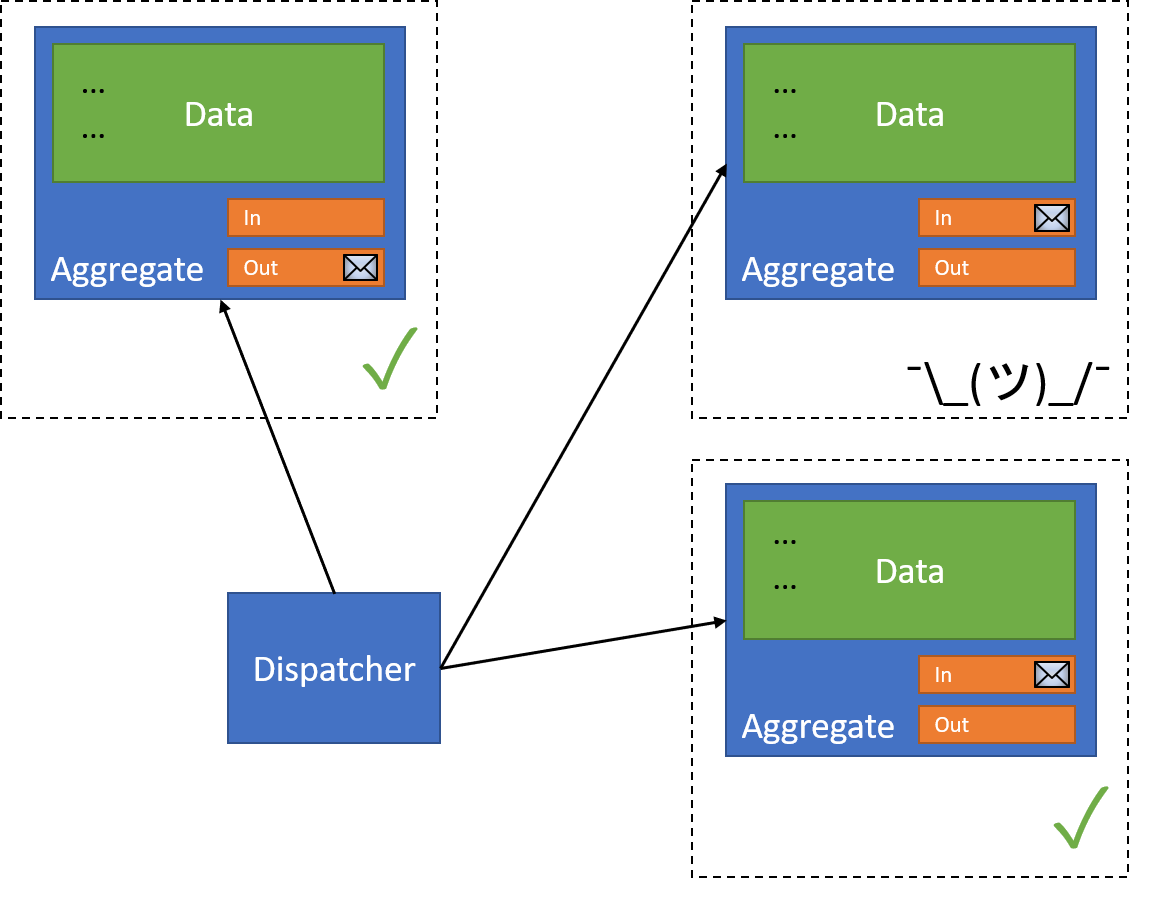
Now that I've completed the first action, I can now begin my interaction with other resources. I use a dispatcher to do so - something that's responsible for reading from a resource's outbox:
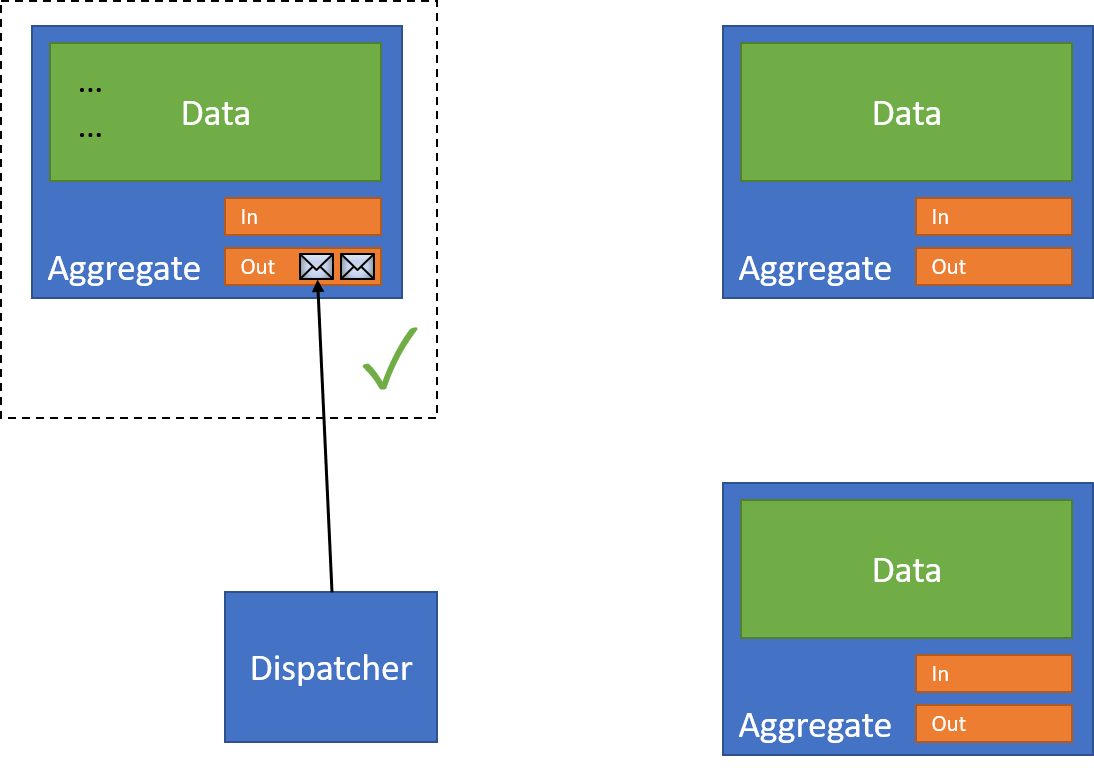
And pass them to the correct resource:
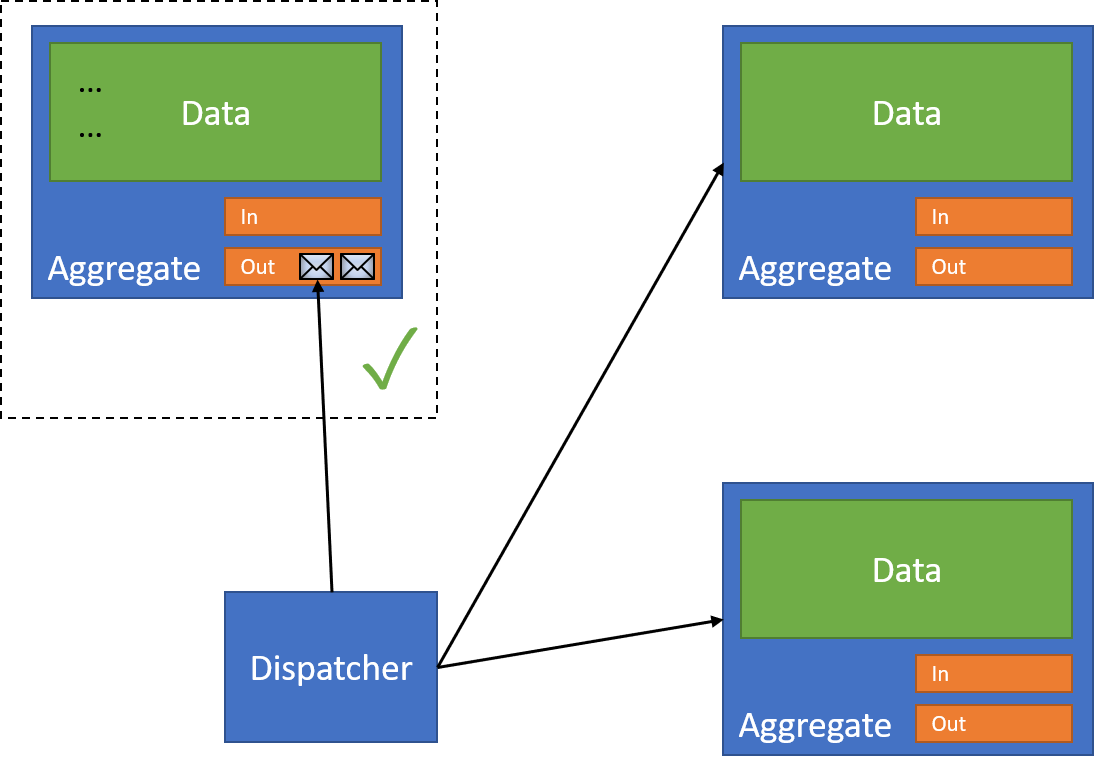
Each resource receives the incoming message, and performs 2 actions:
- Affect the business data
- Store the incoming message in the inbox
This entire operation is transactional:
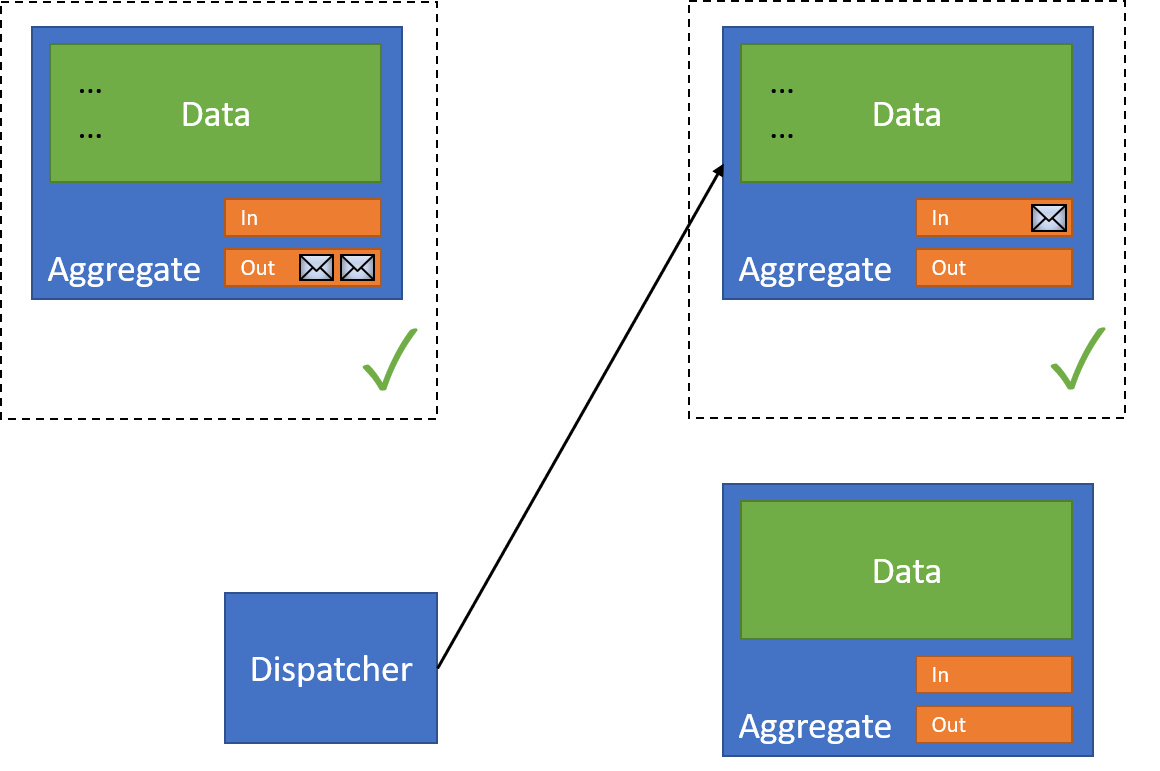
With that resource successful, the dispatcher moves on to the next resource. However, this operation can fail:
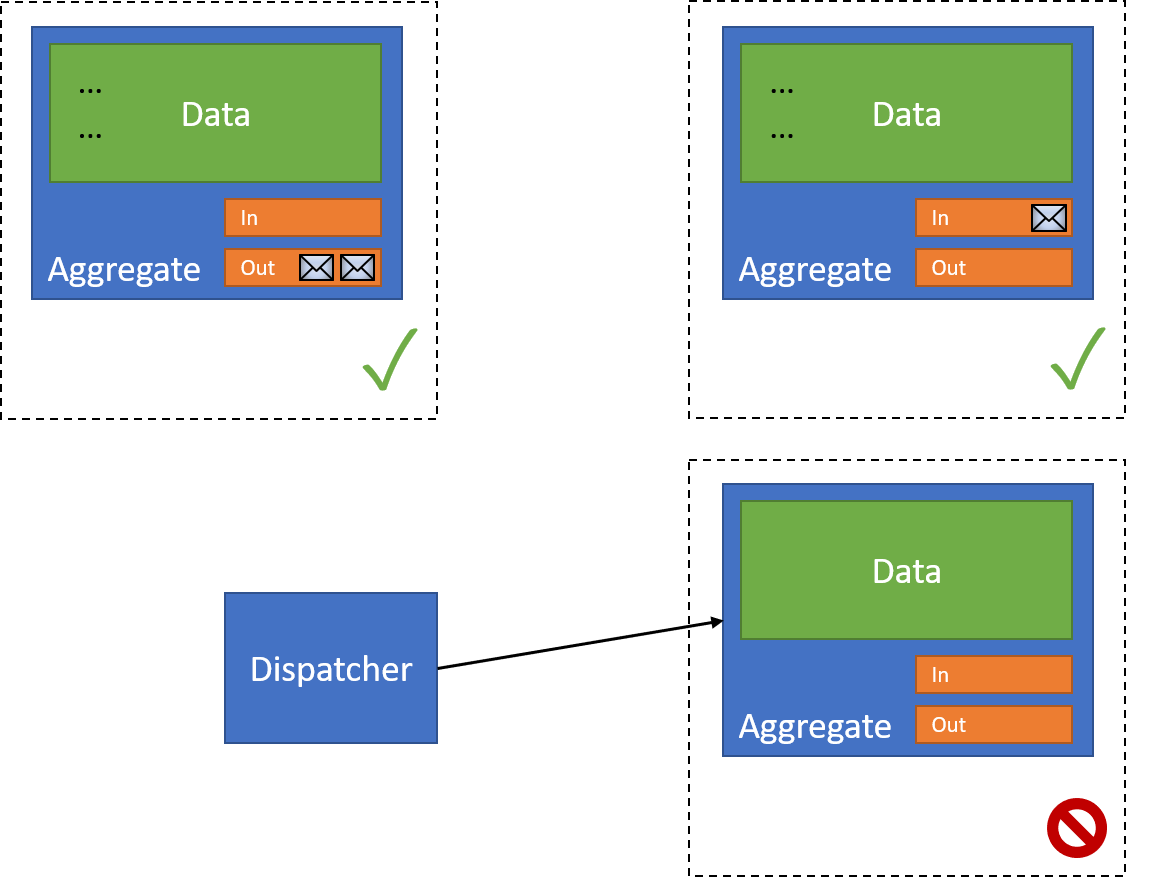
When this happens, we move the message to an external retry queue:
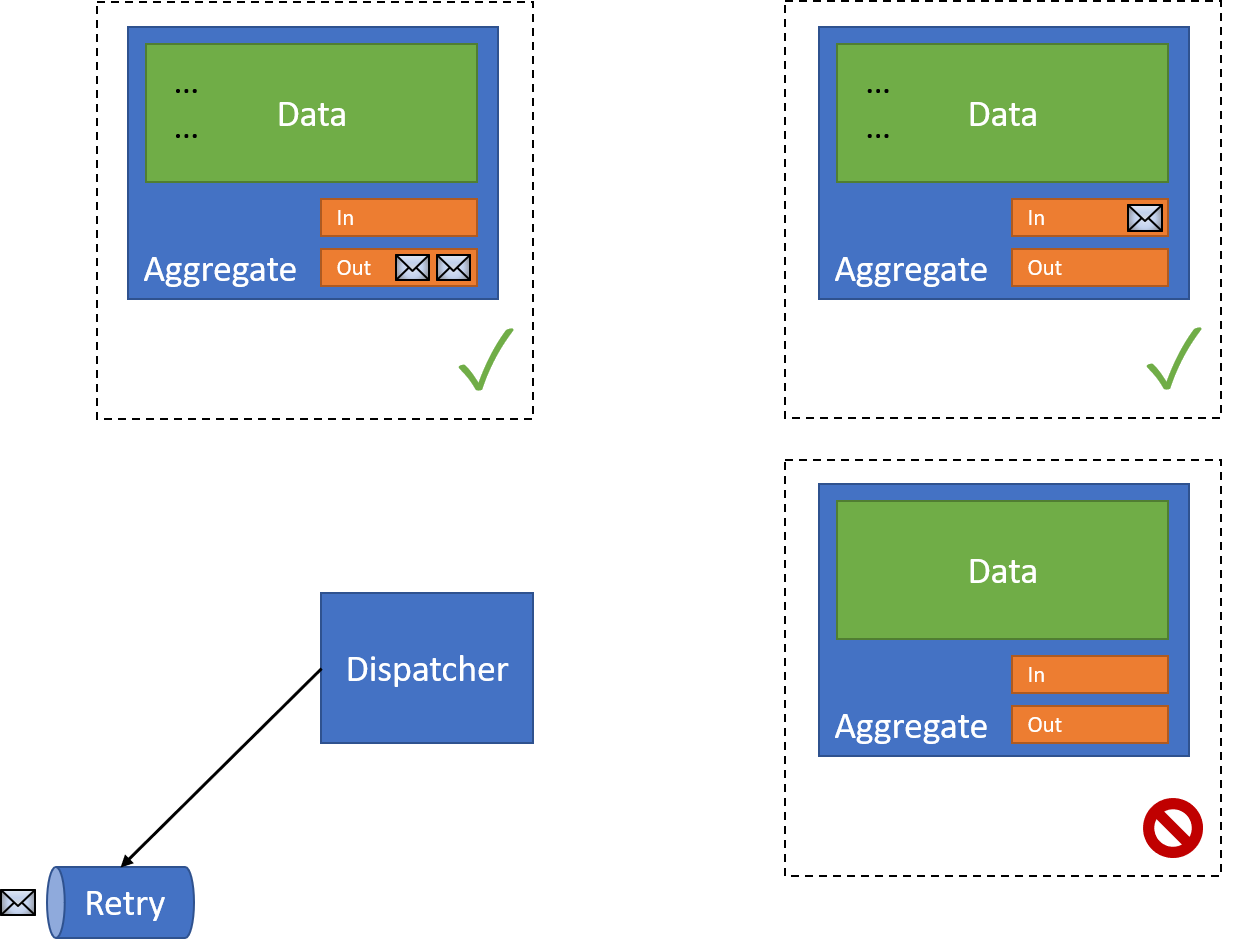
At this point the dispatcher is complete - but because we still have a failed resource, we can't remove our event from the original document's outbox.
Retries
In our half-completed state, we need to re-process the outbox for our document. So our dispatcher wakes up from the Retry message and reads the messages in the original document's outbox:
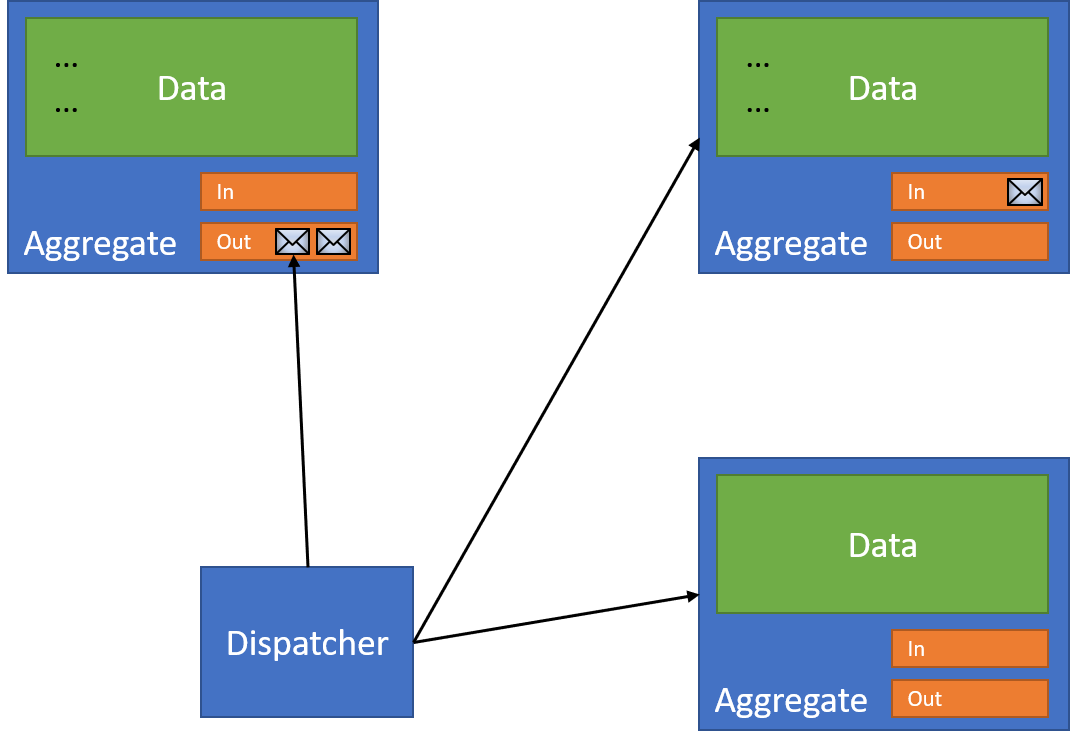
The dispatcher dispatches our message again to each of the receiving resources, processing each one in turn. Our first resource has already processed this message, which it knows because it's checked its Inbox before changing the data (making it idempotent):
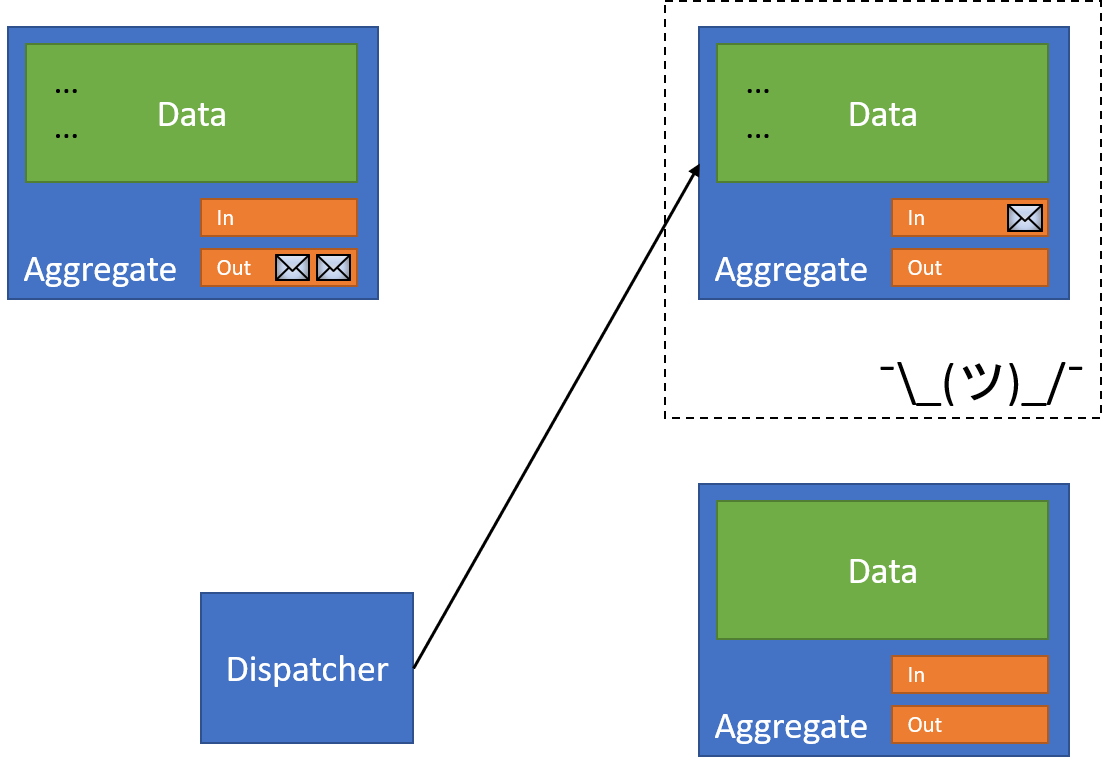
With that complete, the dispatcher can move on to the (previously) failing document:
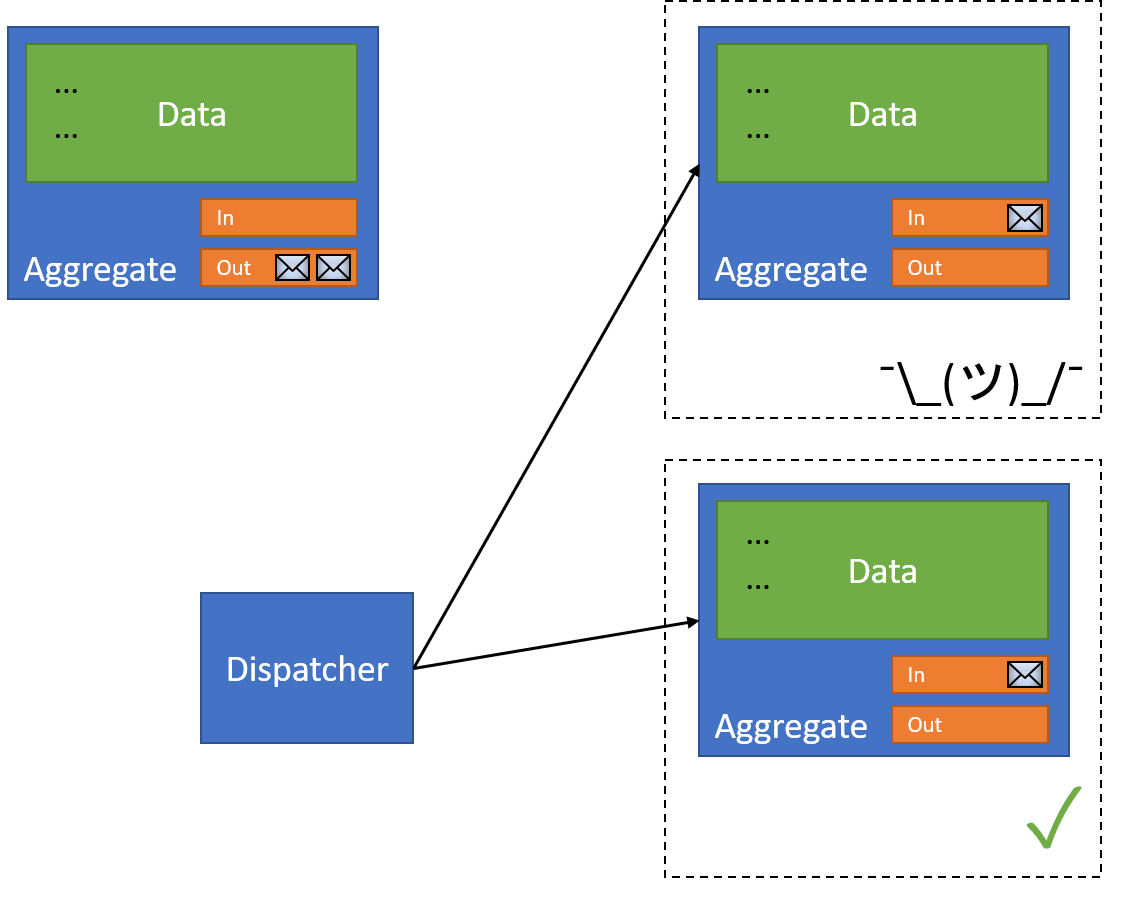
And that document can now succeed. Of course, there might be a bug or something actively preventing us from succeeding - so in that case we'll need to design explicit failure strategies. For now, let's assume that our operations will eventually succeed. Once we've confirmed that we've successfully dispatched our message to all receivers, we can go back to our original document and remove the message:
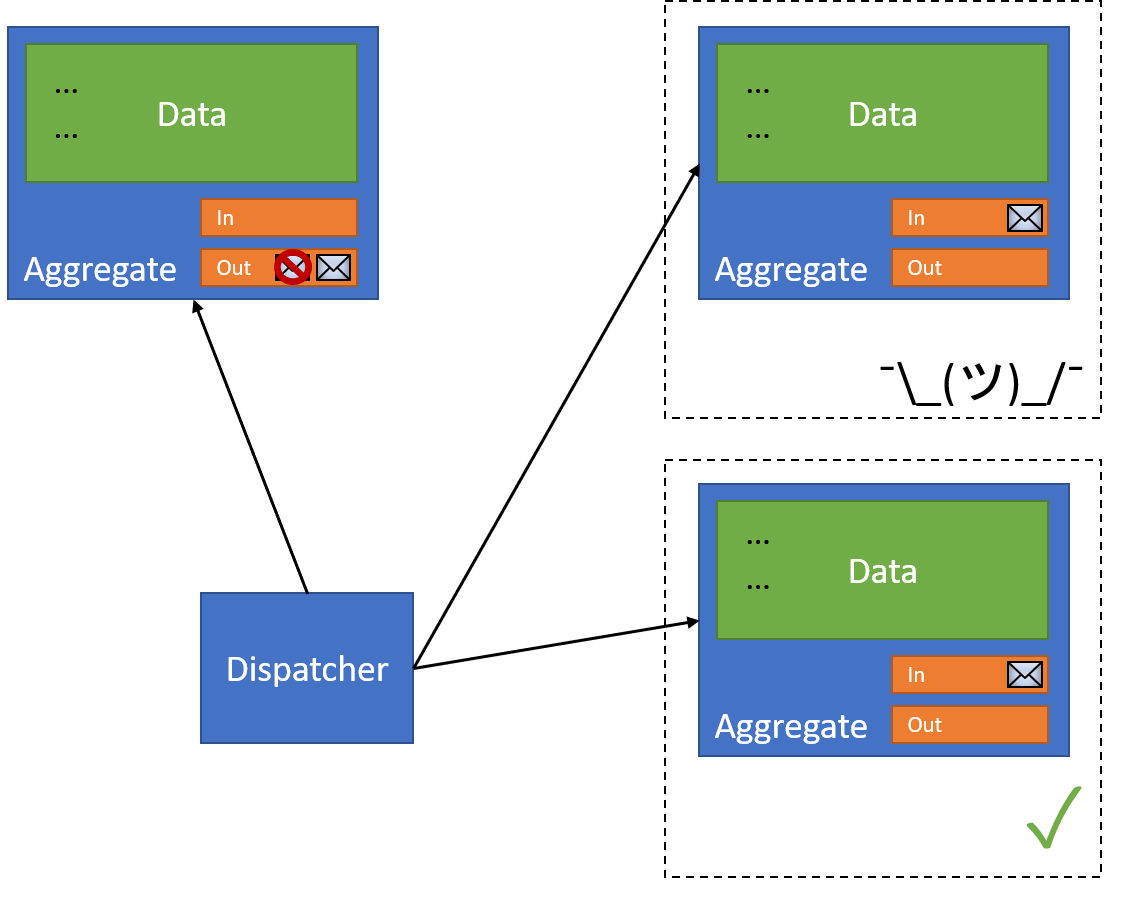
This is then saved in its own individual transaction:
In each step of the way, we have to work in smaller transactional steps that can be individually retried at least once, since each operation is idempotent. By storing our communication in the same transactional boundary of our business data, we can introduce reliable resource coordination when each of our resources isn't able to participate in that transaction.
In the next post, I'll walk through some code examples of this pattern in Cosmos DB.